 |
(1) |
In deriving a gradient-based update rule for recurrent networks, we now make network connectivity very very unconstrained. We simply suppose that we have a set of input units, I = {xk(t), 0<k<m}, and a set of other units, U = {yk(t), 0<k<n}, which can be hidden or output units. To index an arbitrary unit in the network we can use
|
(1) |
Let W be the weight matrix with n rows and n+m columns, where wi,j is the weight to unit i (which is in U) from unit j (which is in I or U). Units compute their activations in the now familiar way, by first computing the weighted sum of their inputs:
 |
(2) |
where the only new element in the formula is the introduction of the temporal index t. Units then compute some non-linear function of their net input
| yk(t+1) = fk(netk(t)) | (3) |
Usually, both hidden and output units will have non-linear activation functions. Note that external input at time t does not influence the output of any unit until time t+1. The network is thus a discrete dynamical system.
Some of the units in U are output units, for which a target is defined. A target may not be defined for every single input however. For example, if we are presenting a string to the network to be classified as either grammatical or ungrammatical, we may provide a target only for the last symbol in the string. In defining an error over the outputs, therefore, we need to make the error time dependent too, so that it can be undefined (or 0) for an output unit for which no target exists at present. Let T(t) be the set of indices k in U for which there exists a target value dk(t) at time t. We are forced to use the notation dk instead of t here, as t now refers to time. Let the error at the output units be
 |
(4) |
and define our error function for a single time step as
 |
(5) |
The error function we wish to minimize is the sum of this error over all past steps of the network
 |
(6) |
Now, because the total error is the sum of all previous errors and the error at this time step, so also, the gradient of the total error is the sum of the gradient for this time step and the gradient for previous steps
 |
(7) |
As a time series is presented to the network, we can accumulate the values of the gradient, or equivalently, of the weight changes. We thus keep track of the value
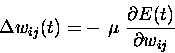 |
(8) |
After the network has been presented with the whole series, we alter each weight wij by
 |
(9) |
We therefore need an algorithm that computes
 |
(10) |
at each time step t. Since we know ek(t) at
all times (the difference between our targets and outputs), we only
need to find a way to compute the second factor 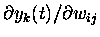 .
.
The key to understanding RTRL is to appreciate what this factor expresses. It is essentially a measure of the sensitivity of the value of the output of unit k at time t to a small change in the value of wij, taking into account the effect of such a change in the weight over the entire network trajectory from t0 to t. Note that wij does not have to be connected to unit k. Thus this algorithm is non-local, in that we need to consider the effect of a change at one place in the network on the values computed at an entirely different place. Make sure you understand this before you dive into the derivation given next
This is given here for completeness, for those who wish perhaps to
implement RTRL. Make sure you at least know what role the factor plays in computing the
gradient.
From Equations 2 and 3, we get
 |
(11) |
where  is the
Kronecker delta
is the
Kronecker delta
 |
(12) |
[Exercise: Derive Equation 11 from Equations 2 and 3]
Because input signals do not depend on the weights in the network,
 |
(13) |
Equation 11 becomes:
 |
(14) |
This is a recursive equation. That is, if we know the value of the left hand side for time 0, we can compute the value for time 1, and use that value to compute the value at time 2, etc. Because we assume that our starting state (t = 0) is independent of the weights, we have
 |
(15) |
These equations hold for all  .
.
We therefore need to define the values
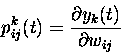 |
(16) |
for every time step t and all appropriate i, j and k. We start with the initial condition
| pijk(t0) = 0 | (17) |
and compute at each time step
 |
(18) |
The algorithm then consists of computing, at each time step t, the quantities pijk(t) using equations 16 and 17, and then using the differences between targets and actual outputs to compute weight changes
 |
(19) |
and the overall correction to be applied to wij is given by
 |
(20) |